-
[논문 읽기] (2017) Dex-Net 2.0논문 읽기/Dex-Net 2022. 3. 22. 14:05
* 요약
강인한 로봇 파지 계획을 위한 딥러닝 데이터셋 수집 시간을 줄이기 위해, 우리는 6.7백만개의 point cloud, 파지, 그리고 분석적 파지 지표에 대한 합성데이터셋으로 학습하는 방법을 조사해보았다. 해당 데이터셋은 책상 위에서 임의의 포즈로 되어있는 Dex-Net 1.0으로부터 수천개의 3D 모델로부터 생성되었다. 우리는 결과 데이터셋을 사용했다, Dex-Net 2.0, GQ-CNN 모델을 학습시키기 위해. depth 이미지로부터 파지 성공률을 빠르게 계산하는 모델. 파지가 RGB-D 센서에 상대적인 평면 위치, 각도, 그리고 그리퍼의 깊이로서 구체화되는. ABB YuMi에 1000번 넘게 시도된 이번 실험은 단일 객체에 대한 파지 계획 방식과 비교했을때, Dex-Net 2.0으로 생성된 합성데이터로만 훈련시킨 GQ-CNN이 93% 성공률과 0.8초 안에 파지가 가능하도록 계획하는데 사용될 수 있다는 것을 제안하였다. 어려운 모양을 가진 알고있는 8가지 객체에 한해서. 객체의 미리 계산된 데이터셋과 indexing 파지에 있어서 point cloud를 등록하는것보다 3배 더 빠른 결과도 보여주었다. Dex-Net 2.0 파지 계획은 10개의 일반적이고 단단한 객체 데이터셋에서 매우 높은 성공률을 보였고, 40개의 가정 물품 데이터셋에서 99% 정밀도를 보였다.
I. 소개
신뢰할만하고 강인한 파지는 정밀하지 않은 sensing과 actuation 때문에 상당히 힘든 과제이다. 이는 객체 모양, 포즈, 재료 성질, 그리고 무게와 같은 성질에 대한 불확실함으로 연결된다. 최근 결과에서는, human grasp labels 혹은 physical grasp outcomes의 대량 데이터셋으로 훈련된 DNN이 이미지나 point cloud로부터 얻은 다양한 객체에 전반적으로 성공적인 파지를 계획하는데 사용될 수 있다고 제안했다. 컴퓨터 비전에서 generalization results와 비슷하게. 그러나, 데이터 수집은 지루한 human labeling이나 실제 시스템에 몇달에 걸친 실행시간을 필요로 한다.
대안적 접근방식은 physics-based 분석을 사용하여 파지를 계획하는 것이다. Physics-based 분석은 caging, grasp wrench space(GWS) 분석, robust GWS 분석, 혹은 시뮬레이션 같은. 클라우드 컴퓨팅을 사용하여 빠른 계산이 가능하다. 그러나, 이 방식은 구분된 인식 시스템을 가정한다. 해당 시스템은 객체 모양이나 포즈와 같은 성질을 완벽히 예측한다. known Gaussian distribution에 따르면. 이것은 에러를 가지치기하기 때문에, 새로운 객체를 일반화하기에 적합하지 않을 수 있다, 그리고 실행 도중에 known model에 point cloud를 연결시키는데 상당히 느릴 수 있다. 이 논문에서 우리는 파지 성공률을 예측한다. 해당 예측은 대량의 데이터셋에 deep CNN을 훈련시켜 depth 이미지로부터 직접적으로 얻어낸다. 데이터셋은 parallel-jaw 파지, 파지 지표, 그리고 강인한 파지와 이미지 형성의 분석적 모델을 사용하여 생성된 rendered point cloud로 되어있다. 해당 알고리즘은 force closure grasp를 분류하고 dynamic 파지 시뮬레이션의 결과에 대한 최근 연구를 바탕으로 제작되었다.
우리의 첫 기여는: 1) Dex-Net 2.0, 6.7백만개의 point cloud로 구성된 데이터셋과 분석적 파지 품질 지표. 분석적 파지 품질 지표는 1500개의 3D 객체 모델 데이터셋에 강인한 quasi-static GWS 분석을 사용하여 계획된 parallel-jaw 파지와 함께. 2) GQ-CNN 모델. 지도학습을 위해 expected epsilon quality를 사용하여 depth 이미지에서 강인한 파지를 분류하기 위해 훈련된 모델. 각 파지가 카메라에 상대적으로 평면인 포즈와 depth로 구체화되어있다. 3) 파지 계획 방법. antipodal 파지 후보를 추출하고, GQ-CNN으로 순위를 매긴다.
ABB YuMi 로봇로 테이블 위에 있는 단일 객체 파지를 첫번이 넘는 실제 시도에서, 우리는 Dex-Net 2.0을 이미지 기반 파지 heuristic, random forest, SVM, 객체를 인식하고 3D 포즈를 등록하며 그리고 실행하기에 가장 강한 파지를 위한 Dex-Net 1.0을 index하는 baseline과 비교한다. 우리는 Dex-Net 2.0 파지 계획이 등록 기반의 방식보다 3배 더 빠르고, 학습에 사용한 객체의 경우 93% 성공률을 보였으며, 일반적인 객체에서는 가장 최고의 수행 방식을 보였다. 합성데이터 전체를 학습시켜 40개의 가정 물품 데이터셋에서 99% 정밀도에 도달했다.
II. 관련 연구
III. 문제 설정
우리는 단단한 단일 객체를 robust planar parallel-jaw 파지를 계획하는 문제를 고려한다. 해당 객체는 depth 카메라로부터 point cloud 기반으로 테이블 위에 놓여있다. 우리는 candidate grasp와 depth image를 입력값으로 하고, estimate of robustness 혹은 불확실한 상황 속에서의 성공률을 결과값으로 가지는 함수를 학습한다.
A. 가정
우리는 parallel-jaw 그리퍼, 평면 작업환경에서의 단단한 단일 객체, 그리고 한쪽에서 바라본(2.5D) point cloud를 가정한다. 데이터셋을 생성하기 위해, 우리는 이미 알려진 그리퍼 구조와 depth 카메라를 사용한다.
B. 정의
1) States x = (O,To,Tc,γ) : 카메라와 객체의 다양한 특징을 표현하는 state
O : 객체의 구조와 무게 성질
To : 객체의 포즈
Tc : 카메라의 포즈
γ : 객체와 그리퍼 사이의 마찰계수 (γ∈R)
2) Grasps u = (p, φ) ∈ R^3 x S1 : 3차원 공간에서 parallel-jaw grasp
p : 카메라에 상대적인 중심점 (x,y,z) ∈ R^3
φ : 책상 평면과의 각도 φ ∈ S1
3) Point Clouds y = R^(HxW)_+ : 카메라로 찍은 높이 H 길이 W인 depth image로 표현된 2.5D point cloud
4) Robust Analytic Grasp Metrics S(u,x) ∈ {0,1} : 이진수의 grasp success metric. 잡기와 들기와 같은.
p(S,u,x,y) : joint distribution. (grasp success, grasps, states, point clouds)
예를 들어, p(S,u,x,y)는 임의의 포즈로 컨베이어 벨트에서 내려오는 잘 알려진 객체를 noisy sensor가 읽어들인 것으로 정의될 수 있다. 관측 결과(grasp u, point cloud y)가 주어질때의 robustness of grasp를, sensing과 control에서의 불확실성 하에서 지표 기대값 혹은 성공 확률이라고 하자:

C. 목표
우리의 목표는 robustness function Qθ*(u,y)가 binary success metric에 따라 grasps를 분류하도록 최대한 많이 파지, 객체, 이미지를 학습하는 것에 있다.

robustness function 
학습 목표 L : 크로스 엔트로피 손실 함수
Θ : GQ-CNN의 파라미터 (섹션 IV-B)
이 목표는 Qθ = Q를 만족하는 몇몇 θ ∈ Θ가 존재할때, 가능한 모든 파지와 이미지에서 Qθ* = Q 를 만족시키기 위한 동기(motivation)로서 작용한다. Estimated robustness function은 파지 후보 세트 중에서 Qθ*를 최대화하는 파지 정책에 사용될 수 있다. C는 충돌이나 역학적 가능성 같이 가능한 파지 세트의 제한 조건을 말한다. policy를 직접 학습하는 것보다 Q를 학습하는 것이 학습 모델을 업데이트할 필요 없이 task-specific 제한조건을 enforce하기에 좋다.
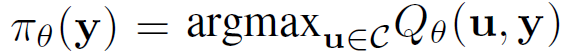
IV. Learning a Grasp Robustness Function
목표 B.1에 있는 grasp robustness function을 푸는 작업은 몇몇 이유 때문에 매우 힘든 과제이다. 첫째로, 우리는 수많은 객체에 대한 기대값에 근사시키기 위해 상당량의 샘플이 필요하다. 우리는 Dex-Net 2.0을 사용하여 이 문제를 해결한다. Dex-Net 2.0은 훈련 데이터셋으로 다음의 요소들로 구성되어 있다. 6.7백만개의 synthetic point clouds, parallel-jaw grasps, 그리고 그림 2에서의 그래픽 모델로부터 샘플링된 1500개의 3D 모델에 걸친 강인한 분석적 파지 지표.
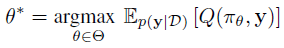
목표 B.1 
그림 2. 그림 2: point cloud 기반의 테이블 표면 위에 있는 객체의 parallel-jaw 파지를 위한 그래픽 모델. 파란 노드는 state 표현에 포함되어있는 변수이다. 객체 모양 O는 객체 모델의 이산적인 세트 위에 일정하게 분포되어 있다. To는 객체의 안정된 포즈와 평면 표면의 일정한 구역 위에 분포되어 있다. 파지 u = (p,φ)는 antipodality 조건을 사용하여 객체 표면으로부터 일정하게 샘플링하였다. 마찰계수 γ이 주어져, 우리는 객체 파지를 위한 분석적 성공 지표 S를 평가한다. 합성 2.5D point cloud y는 카메라 포즈 Tc, 객체 모양 O, 그리고 객체 포즈 To를 기반으로 3D 메쉬로부터 생성된다. 또한, point cloud y는 multiplicative and Gaussian Process noise로 corrupted 된다.
둘째로, 다량의 객체 데이터셋에 걸친 point clouds, grasps, metrics 사이의 관계는 복잡하고 linear or kernelized 모델로는 학습하기 어려울 수 있다. 따라서, 우리는 GQ-CNN 모델을 개발하였다. 해당 모델은 depth 이미지로부터 robust grasp poses를 분류하고, Dex-Net 2.0으로부터 생성된 데이터로 학습할 수 있다.
A. Dataset Generation
우리는 i.i.d 샘플 (S1,u1,x1,y1), ..., (Sn,un,xn,yn) ~ p (S,u,x,y) 을 사용하여 목표 B.1에서 sample approximation을 통해 Qθ*을 예측한다. 샘플은 이미지, 파지, 그리고 성공 지표를 위한 우리의 생성적 그래픽 모델로부터 샘플링된다.

1) 그래픽 모델 : 우리의 그래픽 모델은 그림 2에 표현되어있고, p(S,u,x,y)를 모델링한다. p는 다음의 요소들로 구성된 겨과물이다. state distribution p(x), observation p(y|x), grasp candidate model p(u|x), analytic model of grasp success p(S|u,x)
우리는 state distribution p(x)를 다음과 같이 모델링한다.
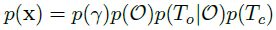
각 distribution은 Table I에 설명되어있다.

Table I TABLE I: Dex-Net 2.0 그래픽 모델에 사용된 distribution의 detail. Dex-Net 훈련 데이터셋을 생성하는데 사용된다.
우리의 파지 후보 모델 p(u|x)는 객체 표면에 있는 한쌍의 antipodal contact points에 대한 uniform distribution이다. 해당 contact points는 테이블 평면에 평행한 grasp axis를 가진다. 우리의 observation model은 다음의 공식으로 표현된다.
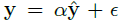
여기서 yhat은 주어진 포즈의 주어진 객체에 대한 rendered depth image이다. α는 깊이에 비례하는 노이즈를 모델링한 Gamma random variable이다. ε은 픽셀 좌표에 0을 평균으로하는 가우시안 프로세스 노이즈이다. 우리는 grasp success를 다음과 같이 모델링한다.

여기서 Eq는 [51]에 정의된 robust epsilon quality로서, 마찰과 그리퍼 포즈로 인한 불확실성을 포함하는 다양한 포즈 오류에 강인한 지표이다. 그리고 collfree(u,x)는 객체나 테이블에 그리퍼가 충돌하지 않는다는 것을 의미한다. 보충자료에서 자세한 파라미터를 확인할 수 있다.
2) Database : Dex-Net 2.0은 그림 3과 같은 pipeline을 사용하여 생성된 6.7백만개의 datapoints를 가지고 있다.

그림 3. 그림 3: 훈련 데이터셋 생성을 위한 Dex-Net 2.0 pipeline. (왼쪽) 데이터베이스는 1500개의 3D 객체 메쉬 모델을 가지고 있다. (위) 각 객체마다, 우리는 표면을 덮고 샘플링을 사용하여 robust analytic grasp metrics를 평가하기 위해 수백개의 parallel-jaw grasps를 샘플링한다. 객체의 안정된 포즈마다, 우리는 테이블에 수직이고 주어진 그리퍼 모델이 충돌하지 않는 파지 세트를 연결시킨다. (아래) 우리는 각각의 안정된 포즈를 가진 각 객체의 point clouds를 만들어낸다. 이때 객체는 평면의 객체 포즈를 가지고 있고, 카메라 포즈는 무작위로 uniform하게 샘플링된다. 주어진 안정된 포즈에 대한 모든 파지는 rendered image에서의 픽셀 위치와 방향성과 연관되어 있다. (오른쪽) 이미지 중심에 파지 픽셀 위치를 정렬하고, 이미지의 중간 행에 파지축을 정렬하기 위해, 각 이미지는 회전되고, 이동되고, 잘라내고, 크기를 조정하여, 32 x 32 크기의 grasp image를 생성한다. 전체 데이터셋은 6.7백만개의 grasp images를 가지고 있다.
3D Models. 데이터베이스는 Dex-Net 1.0으로부터 1500개 메쉬 모델의 부분집합을 담고 있다. 참고로, Dex-Net 1.0은 3DNet의 1371개 합성 모델과 KIT 객체 데이터베이스의 129개 레이저 스캔으로 구성되어 있다. 각 메쉬는 principal axes를 사용하여 standard frame of reference에 정렬되어있고, 그리퍼 사이즈 5.0cm에 맞게 크기가 재조정되었으며, 몇몇 메쉬는 닫혀있지 않기 때문에, object bounding box의 중심에 1.0kg 무게를 할당하였다. 각 객체마다, 우리는 안정된 포즈 세트를 계산하고 threshold보다 큰 발생확률을 가지고 안정된 포즈는 모두 저장하였다.
Parallel-Jaw Grasps. 각 객체는 100개의 parallel-jaw grasps 까지 label된다. 파지는 antipodal point pairs를 위한 rejection sampling method를 사용하여 객체 표면에 coverage를 주는 제한조건과 함께 샘플링된다. 이 방법은 Dex-Net 1.0에서 개발되었다. 각 파지마다, 우리는 Monte-Carlo 샘플링을 사용하여 객체 포즈, 그리퍼 포즈, 그리고 마찰 계수 불확실성 하에서 expected epsilon quality Eq[42]를 계산했다.
Rendered Point Clouds. 모든 객체는 안정된 포즈에서의 2.5D point clouds (depth images)와 같이 있다. 섹션 IV-A1에 표현된 그래픽 모델에 따라 샘플링된 카메라 포즈와 평면 객체 포즈와 함께. 이미지는 pinhole camera model과 카메라 perspective projection을 사용하여 만들어진다. 그리고 각 rendered image는 픽셀 이동을 사용하여 관심있는 객체를 중앙에 위치시킨다. 훈련 동안 이미지에 노이즈가 추가되고, 이는 섹션 IV-B3에 표현되어있다.
B. Grasp Quality Convolutional Neural Network
1) 구조 : GQ-CNN 구조는 grasp robustness function Qθ를 표현하기위해 사용된 파라미터 Θ 세트를 정의한다. 해당 구조는 그림 4에 표현되어있다.

그림 4. 그림 4: (왼쪽) GQ-CNN 구조. Planar grasp candidates u = (i,j,φ,z)는 depth image로부터 생성되고, 파지 중심 픽셀 (i,j)와 방향 φ에 이미지를 정렬하기 위해 이동된다. 구조는 다음의 layer로 구성되어있다. 4개의 convolutional layers가 ReLU와 짝지어 있고, 3개의 fully connected layers가 그 뒤를 잇는다. 또한, z를 위한 또다른 input layer가 있다. z는 카메라로부터 그리퍼의 거리를 나타낸다. convolutional layers의 사용은 이전 연구에서 학습의 특징으로서 depth edge의 관련성에 의해 motivate된다. 그리고 ReLU의 사용은 이미지 분류 결과에 의해 motivate된다. 네트워크는 grasp success (robustness) Qθ ∈ [0,1] 확률을 예측한다. 이는 grasp candidates의 순위로서 사용될 수 있다. (오른쪽) Dex-Net 2.0에서 GQ-CNN으로 학습한 convolutional filter의 첫번째 layer. 필터는 다양한 크기에서 방향성을 가지는 이미지 gradients를 계산하기 위해 있다. 이러한 필터는 접촉점에서의 normal vector와 그리퍼와 객체 사이 충돌을 추론하는데 사용된다.
GQ-CNN은 카메라 z로부터의 gripper depth와 파지 중심 픽셀 v = (i,j)에 중심을 맞추고 파지축 방향 φ로 정렬한 depth image를 입력값으로 받는다. 이미지와 그리퍼 간 정렬은 다양한 회전에 대해 학습할 필요를 없앤다. 그리고 이미지에서의 어떤 파지 방향이든 네트워크가 계산할 수 있게 도와준다. 표준 전처리에 따라, 우리는 입력 데이터를 학습 데이터의 평균값으로 빼고 표준편차로 나눈뒤, 파지 강도를 예측하기 위해 이미지와 그리퍼 depth를 네트워크에 통과시킨다. GQ-CNN은 대략 18백만 파라미터를 가진다.
2) 훈련 데이터셋 : GQ-CNN 훈련 데이터셋은 그림 3에서 표현되어있는것처럼 rendered depth image에 상대적인 픽셀 v, 방향 φ, depth z와 grasps를 연결시켜 생성된다. 우리는 카메라 포즈 Tc를 사용하여 카메라 프레임에 파지를 transform하고, 3D 파지 포지션과 방향을 카메라의 imaging 평면에 project하여, 앞선 파라미터를 계산한다. 그리고나서, 우리는 모든 이미지와 파지 쌍을 v에 중심이 맞춰지고 φ에 방향이 맞춰진 단일 이미지에 이동시킨다. (그림 4의 왼쪽과 같이) Dex-Net 2.0 학습 데이터셋은 6.7백만 datapoints를 가지고 있고, threshold δ = 0.002를 가지는 thresholded robust epsilon quality와 custom YuMi 그리퍼와 함께 거의 21.2% positive examples를 가지고 있다.
3) 최적화 : 우리는 SGD와 momentum으로 역전파를 사용해 GQ-CNN의 파라미터를 최적화한다. 우리는 평균 0 분산 2/ni인 가우시안 분포에서 샘플링하여 모델의 weights를 초기화한다. 여기서 ni는 i번째 네트워크 레이어에 들어가는 입력 갯수이다. 데이터셋을 augment하기 위해서, 우리는 가로축과 세로축으로 이미지를 뒤집고, 각 이미지를 180도 회전 시키기도 하였다. 이러한 변형이 가능한 이유는 모든 동등한 파지를 갖기 때문이다. 우리는 훈련 도중 새로운 샘플에 대한 batch gradient를 계산하기 전에 우리의 노이즈 모델(섹션 IV-A1)로부터 이미지 노이즈를 샘플링하였다. 각 이미지의 여러 버전을 명백히 저장하지 않고 이미지 노이즈를 모델링하기 위해. 노이즈 샘플링 속도를 높이기 위해, 우리는.
V. Grasp planning
Dex-Net 2.0 grasp planner는 그림 1에서 표현되어 있듯이 robust grasping policy를 사용한다.
the robust grasping policy 
그림 1. 그림 1 : Dex-Net 2.0 구조. (중심) GQ-CNN은 depth images로부터 robustness candidate grasps를 예측하기 위해 훈련된다. 이 훈련에서 Dex-Net 1.0에서 계산된 6.7백만개의 synthetic point clouds, grasps, associated robust grasp metrics가 사용된다. (왼쪽) 객체가 로봇에 주어지면, depth camera는 3D point cloud를 반환한다. 그리고나서 antipodal points 쌍이 수백개의 파지 후보 세트를 만들어낸다. (오른쪽) GQ-CNN은 가장 강인한 파지 후보를 빠르게 결정한다. 그리고나서 ABB YuMi 로봇으로 이 후보가 실행된다.
세트 C는 서로 다른 antipodal candidate grasps 세트이다. 해당 파지는 depth image gradients에 의해 정의된 표면 normal vectors를 위해 이미지 공간에서 무작위로 uniform하게 샘플링되었다. 각 파지 후보는 GQ-CNN으로 평가되었다. 그리고 그중에서 (a) 역학적으로 가능하고 (b) 테이블과 충돌하지 않는 가장 강인한 파지가 실행되었다.
Appendix B. Grasp Sampling Methods
A. Antipodal Grasp Sampling
이 논문에서 사용한 antipodal grasp sampling은 테이블 관점에서 평면인 포즈, 각도, 그리고 높이로 구체화된 antipodal grasps를 샘플링하도록 디자인되었다. 알고리즘은 Algorithm 1에 상세히 구현되어있다.

우리는 높은 그라디언트값을 지니는 영역을 찾기 위해 depth image에 threshold 처리했다. 그리고나서, 우리는 antipodal grasps 후보를 생성하기 위해, 픽셀 쌍에 rejection sampling을 사용했다. 작은 마찰 계수로는 원하는 숫자만큼의 후보가 생성되지 않을 경우, 원하는 후보 갯수에 도달할때까지 마찰 계수를 조금씩 증가시켰다. 우리는 이미지 공간에서의 antipodal grasps를 3D 공간으로 이동시켰다. 이는 파지 중심 픽셀의 상대적 높이와 테이블 표면의 높이 사이에서 그리퍼 높이를 별개로 구분하여 진행된다.
grasp sampling method는 이 논문에서 grasp planners에 기반한 모든 이미지에 사용되었다.
B. Derivative Free Optimization
정해진 후보 세트로부터 파지를 선정하는 과정에서 한가지 문제가 발생한다. 그 문제는 후보 세트가 모두 낮은 성공확률을 가질때 발생한다. 이 문제는 객체가 매우 적은 세트로부터 파지를 해야할때 매우 어려운 문제가 된다. 그림 9 오른쪽 예시와 같이 실패가 발생한다.
우리의 두번째 일반화 연구에서, 우리는 가장 강인한 파지로 최적화하기 위해 크로스 엔트로피 방식 (CEM)을 사용하여 이 문제를 해결했다. CEM은 derivative-free optimization의 형태를 지닌다. 이 최적화는 강인한 파지들에 대한 하습 분포로부터 파지점을 반복적으로 리샘플링하고 분포를 업데이트하여 진행된다. 이 방식은 알고리즘 2에 나타나 있으며, 가우시안 혼합 모델 (GMM)을 사용하여 유망한 파지점에 대한 분포를 모델링하고, 마찰계수를 반복적으로 업데이트하지 않은 상태에서 알고리즘 1을 사용하여 antipodal point pairs로 최초의 파지 세트를 뿌려둔다. 알고리즘의 입력값과 출력값은 다음과 같다.
- 입력값
m : the number of CEM iterations = 3
n : the number of initial grasps to sample = 100
c : the number of grasps to resample from the model = 50
k : the number of GMM mixture components = 3
μ : a friction coefficient = 0.8
γ : elite percentage = 25%
Qθ : GQ-CNN
- 출력값
u : an estimate of the most robust grasp

'논문 읽기 > Dex-Net' 카테고리의 다른 글
[논문 읽기] Dex-Net 목차정리 (0) 2022.03.30 [논문 읽기] (2017) Learning Deep Policies for Robot Bin Picking by Simulating Robust Grasping Sequences (0) 2022.03.28 [논문 읽기] (2016) Dex-Net 1.0 (0) 2022.03.22 [논문 읽기] (2019) Dex-Net 4.0 : Learning ambidextrous robot grasping policies (0) 2022.03.18 [논문 읽기] (2018) Dex-Net 3.0 (0) 2022.03.11