-
[논문 읽기] (2020) Deep Learning for 3D Point Clouds: A Survey논문 읽기 2022. 3. 17. 12:01
* 요약
point cloud learning은 컴퓨터 비전, 자율 주행, 로봇 등 다양한 영역에서 넓게 적용되어 최근 많은 주목을 받고있다. AI에서 지배적인 기술로서, 딥러닝은 다양한 2D vision 문제들을 성공적으로 해결해왔다. 그러나, point cloud를 DNN으로 작업하는 어려운 과제로 인해 point cloud에 적용되는 딥러닝은 여전히 낮은 단계에 머물러있다. .최근, point cloud 딥러닝 기술은 빠르게 발달하고 있다. 미래의 연구를 위해서, 이 논문을 통해 point cloud 딥러닝에 관한 최근 연구들을 전반적으로 리뷰해보았다. 이 논문은 크게 세가지 주요 task를 다룬다 : 3D shape classification, 3D object detection and tracking, 3D point cloud segmentation. 이 논문은 공개데이터셋을 사용하여 각 알고리즘의 성능을 비교하였다. 나아가, 깊은 차원의 관찰 결과와 미래 연구 방향성에 대해 언급해놓았다.
============================================================================
1. 소개
2. 배경
3. 3D Shape Classification
4. 3D Object Detection and Tracking
5. 3D Point Cloud Segmentation
6. Conclusion
============================================================================
1. 소개
2. 배경
2.1 데이터셋
2.2 평가 지표
3. 3D Shape Classification
3.1 Multi-view based Methods
3.2 Volumetric-based Methods
3.3 Point-based Methods
3.4 Summary
4. 3D Object Detection and Tracking
4.1 3D Object Detection
4.2 3D Object Tracking
4.3 3D Scene Flow Estimation
4.4 Summary
5. 3D Point Cloud Segmentation
5.1 3D Semantic Segmentation
5.2 Instance Segmentation
5.3 Part Segmentation
5.4 Summary
6. Conclusion
============================================================================
1. 소개
2. 배경
2.1 데이터셋
2.2 평가 지표
3. 3D Shape Classification
3.1 Multi-view based Methods
3.2 Volumetric-based Methods
3.3 Point-based Methods
3.3.1 Pointwise MLP Methods
3.3.2 Convolution-based Methods
3.3.3 Graph-based Methods
3.3.4 Hierarchical Data Structure-based Methods
3.3.5 Other Methods
3.4 Summary
4. 3D Object Detection and Tracking
4.1 3D Object Detection
4.1.1 Region Proposal-based Methods
4.1.2 Single Shot Methods
4.2 3D Object Tracking
4.3 3D Scene Flow Estimation
4.4 Summary
5. 3D Point Cloud Segmentation
5.1 3D Semantic Segmentation
5.1.1 Projection-based Methods
5.1.2 Discretization-based Methods
5.1.3 Hybrid Methods
5.1.4 Point-based Methods
5.2 Instance Segmentation
5.2.1 Proposal-based Methods
5.2.2 Proposal-free Methods
5.3 Part Segmentation
5.4 Summary
6. Conclusion
============================================================================
1 소개
3D 기술의 획기적인 발전에 따라, 3D 센서는 더욱 이용가능해졌다. 3D 센서는 다양한 종류의 3D 스캐너, 라이다, RGBD 카메라(Kinect, RealSense, Apple depth camera)로 구성되어있다. 센서로 획득한 3D 데이터는 geometric, shape, scale의 다양한 정보를 제공할 수 있다. 2D 이미지로 보완되면서, 3D 데이터는 기계를 위해 주변환경에 대한 더 많은 정보를 제공하고 있다. 3D 데이터는 서로 다른 영역에서 수맣은 적용 사례를 보여준다. 자율 주행, 로봇, 원거리 센싱, 의료 기술 등의 사례가 있다.
3D 데이터는 여러가지 형식으로 표현될 수 있다. depth image, point cloud, mesh, volumetric grid 등이 그 예이다. 자주 사용되는 형식으로서, point cloud 표현 방식은 discretization 없이 3D 공간에서 고유의 geometric 정보를 가지고 있다. 그러므로, 자율주행이나 로봇 같이 related application을 이해하기 위해 많은 scene에서 선호되는 방식이다. 최근, 딥러닝 기술은 많은 연구 분야에서 최고의 성과를 내고 있다. 이를테면 컴퓨터 비전, speech recognition, 자연어 처리 등. 그러나, 3D point cloud에서 사용되는 딥러닝은 여전히 몇몇 중요한 도전과제에 직면해있다. 이를테면 적은 데이터셋, 고차원, 3D point cloud의 비구조화된 상태 등. 이러한 제반 사정 위에서, 이 논문은 3D point cloud를 처리하는데 사용되는 딥러닝 기술을 분석하였다.
point cloud 딥러닝은 특히 최근 5년동안 수많은 주목을 받고 있다. 몇몇 공개데이터셋이 배포되었다. 이를테면 ModelNet, ScanObjectNN, ShapeNet, PartNet, ... 등. 이 데이터셋은 3D point cloud 딥러닝 연구에 박차를 가했다. point cloud processing, 3D shape classification, 3D object detection and tracking, 3D point cloud segmentation, 3D point cloud registration, 6-DOF pose estimation, 3D reconstruction과 과년된 다양한 문제들을 해결하기 위해 제안된 수많은 연구들과 함께. 3D 데이터 딥러닝에 관한 조금 다른 연구들도 존재한다. 그러나, 우리의 논문은 point cloud 이해를 위한 딥러닝 방법에 구체적으로 집중한다. 3D point cloud를 위한 기존의 딥러닝 분류체계는 그림 1과 같다.

이 연구의 기여는 다음과 같이 요약될 수 있다:
1) 우리가 알기로는, 몇몇 중요한 point cloud 이해 업무를 위한 딥러닝 기술을 전반적으로 다룬 첫번째 연구 논문이다.
2) 기존의 리뷰와는 달리, 우리는 모든 종류의 3D 데이터가 아닌 3D point cloud를 위한 딥러닝 기술에 구체적으로 집중했다.
3) 이 논문은 point cloud에 대한 딥러닝의 최신 흐름을 반영했다. 그러므로, 이 논문은 독자들로 하여금 최신의 기술을 제공한다.
4) 공개데이터셋을 활용한 기존 연구의 전반적 비교가 제공되었다. 짧은 요약과 깊은 차원의 논의도 함께 제공된다.
이 논문의 구조는 다음과 같다. 섹션 2에서는 각 task의 데이터셋과 평가지표를 소개한다. 섹션 3에서는 3D shape classification을 검토한다. 섹션 4에서는 3D object detection and tracking을 검토한다. 섹션 5에서는 point cloud segmentation을 검토한다. 마지막으로, 섹션 6에서는 이 논문의 결론을 담았다. 우리는 또한 주기적으로 업데이트되는 project page를 제공한다.
https://github.com/QingyongHu/SoTA-Point-Cloud
2. 배경
2.1 데이터셋
수많은 데이터셋이 서로다른 3D point cloud 적용을 위한 딥러닝 알고리즘의 성능을 평가하기 위해 수집되었다. 테이블 1은 3D shape classification, 3D object detection and tracking, and 3D point cloud segmentation에 사용되는 전형적인 데이터셋을 담았다. 특히, 이 데이터셋의 특징을 요약하였다.
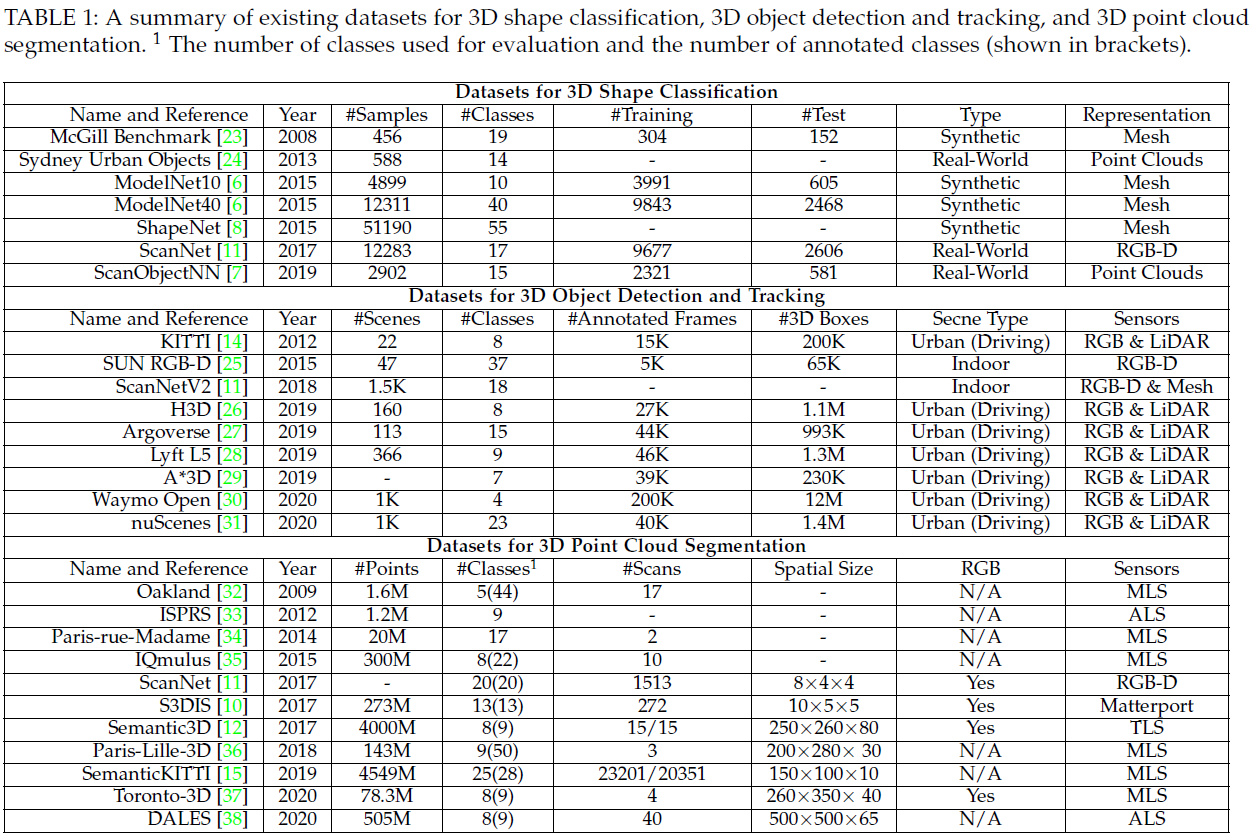
3D shape classification을 위해서, 두가지 종류의 데이터셋: 합성 데이터셋과 실제 데이터셋이 있다. 합성 데이터셋에서의 객체는 완벽하다. occlusion도 없고, 배경도 없다. 대조적으로, 실제 데이터셋에서의 객체는 서로 다른 레벨에서 occlude 되어있다. 그리고 몇몇 객체는 배경 noise로 오염되어 있기도하다.
3D object detection and tracking을 위해서, 두가지 종류의 데이터셋: 실내의 장면과 실외의 장면이있다. 실내 데이터셋의 point cloud는 dense depth maps으로부터 만들어지거나 3D mesh로부터 sample된 것이다. 실외 데이터셋은 자율주행을 위해 디자인되었다. 객체가 공간적으로 잘 분리되어있고, 이러한 point cloud의 밀도가 낮다.
3D point cloud segmentation을 위해서, 다양한 종류의 센서로부터 데이터셋이 얻어진다. Mobile Laser Scanner, Aerial Laser Scanner, static Terrestrial laser Scanners, RGBD 카메라 그리고 그외 3D 스캐너 등. 이러한 데이터셋은 다양한 도전과제에 직면한 알고리즘을 개발시키는데 사용될 수 있다. 비슷한 것끼리 구별, 완전하지 않은 모양, 클래스간 크기 차이.
2.2 평가 지표
서로 다른 평가 지표는 다양한 point cloud 이해를 위해 제안되었다. 3D shape classification을 위해서, Overall Accuracy(OA)와 mean class accuracy(mAcc)는 수행 평가 기준에 빈번히 사용된다. 'OA"는 모든 테스트 에서의 평균 정확도를 나타내고, 'mAcc'는 모든 shape class의 평균 정확도를 나타낸다. for 3D object detection을 위해서, Average Precision(AP)이 빈번히 사용된다. AP는 precision-recall 커브 아래의 면적으로 계산된다. Precision and Success는 3D 단일 객체 tracker의 전반적인 성능을 평가하기 위해 주로 사용된다. Average Multi-Object Tracking Accuracy(AMOTA)와 Average Multi-Object Tracking Precision(AMOTP)는 3D 여러 객체 tracking의 평가 기준으로 빈번히 사용된다. 3D point cloud segmentation을 위해서, OA, mean Intersection over Union(mIoU), mean class Accuracy(mAcc)가 평가 지표로 사용된다. 특히, mean Average Pecision은 3D point cloud의 instance segmentation에 사용된다.
- 3D shape classification : Overall Accuracy(OA), mean class accuracy(mAcc)
- 3D object detection : Average Precision(AP)
- 3D 단일 객체 tracking : Precision and Success
- 3D 다수 객체 tracking : Average Multi-Object Tracking Accuracy(AMOTA), Average Multi-Object Tracking Precision(AMOTP)
- 3D point cloud segmentation : OA, mean Intersection over Union(mIoU), mean class Accuracy(mAcc)
- 3D point cloud instance segmentation : mean Average Pecision
# 빈피킹의 경우, 한 이미지에서 한 종류의 객체가 어디에 있는지, 어떤 포즈로 있는지 확인해야 한다.
# 3D object detection이나 3D point cloud instance segmentation 중 하나에 원하는 연구가 있을 것 같다.
3. 3D Shape Classification
이 업무를 위한 알고리즘은 aggregation method를 사용하여 전체 point cloud로부터 먼저 각 point의 embedding을 학습하고 global shape embedding을 추출한다. Classificatin은 몇몇 FC layer에 global embedding을 주어서 최종적으로 도달한다. NN에 사용되는 입력의 데이터 종류에 따르면, 현존하는 3D shape classification method는 multi-view based, volumetric-based, point-based method로 구분된다. 몇몇 중요한 methods는 그림2에 표현하였다.
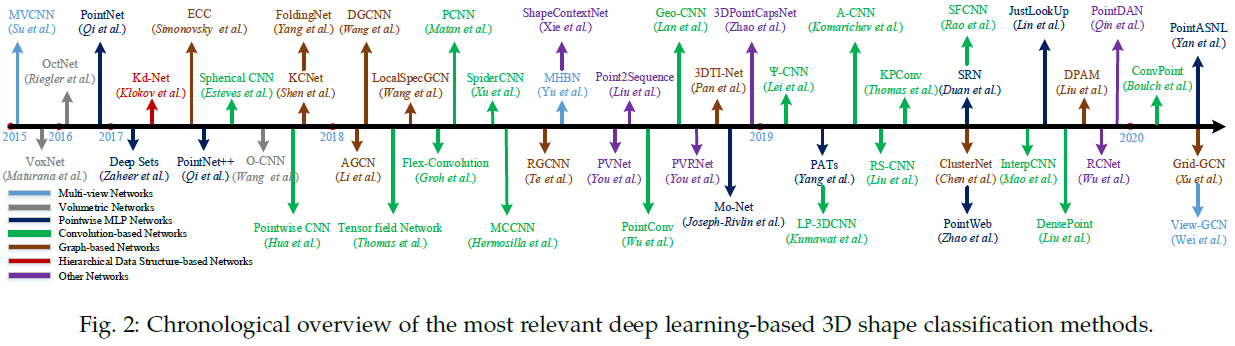
Multi-view based method는 2D 이미지에 비구조화된 point cloud를 project한다. 반면, volumetric-based method는 3D volumetric 표현에 point cloud를 convert한다. 그리고나서, 제대로 제작된 2D나 3D convolutional 네트워크는 shape classification을 수행하기 위해 제작된다. 대조적으로, point-based methods는 voxelization이나 projection 없이 raw point cloud에 직접적으로 사용된다. Point-based method는 explicit information loss를 보여주지 않고 점점 더 인기가 많아지고 있다. 이 논문은 point-based method에 주로 집중하지만, 완벽함을 위해서 몇몇 multi-view based, volumetric-based method를 포함했다.
3.4 요약
ModelNet10/40 데이터셋은 3D shape classification을 위한 데이터셋에 빈번히 사용된다. 테이블 2에서는 다양한 point-based 네트워크로 얻어진 결과를 보여준다. 특이점은 다음과 같이 도출되었다:
- 픽셀단위의 MLP 네트워크는 픽셀단위 특징을 학습하기 위해 다른 종류의 네트워크의 기본 building block에 주로 사용된다.
- 표준 딥러닝 네트워크로서, convolution-based 네트워크는 비전형적인 3D point cloud에서 높은 성과를 보인다. 비전형적 데이터를 위한 discrete convolution 네트워크와 continuous convolution 네트워크에 더 많은 관심이 필요하다.
- 비전형적 데이터를 다루기 위해 내재하는 강한 능력 때문에, graph-based 네트워크는 최근 많은 관심을 받고 있다. 그러나, spectral domain에서의 graph-based 네트워크를 다양한 graph 구조로 확장하는데 여전히 많은 도전과제가 산적해있다.
4. 3D Object Detection and Tracking
이 섹션에서는, 3D object detection, 3D object tracking, 3D scene flow estimation에 대한 기존 연구를 검토해본다.
4.1 3D Object Detection
전형적인 3D object detector는 한 장면의 pint cloud를 입력값으로 받고, 탐색된 각 객체 주위의 oriented 3D bounding box를 출력한다. 그림 6처럼. 이미지 객체 탐지와 같이, 3D 객체 탐지는 두 종류로 구분된다: region proposal-based, single shot. 몇몇 주요 알고리즘을 그림 7에서 소개한다.


4.4 요약
KITTI benchmark는 자율 주행에서 가장 영향력있는 데이터셋 중에 하나이고, 학계나 산업계에서 주로 사용되어왔다. 테이블 3과 4는 KITTI 테스트 3D benchmark에 서로 다른 detector로 얻어낸 결과를 보여준다. 그 결과, 다음과 같은 관찰 결과를 받아 볼 수 있었다:
- Region proposal-based method는 두가지 카테고리 사이에서 가장 빈번히 조사된 method이다. 그리고 KITTI 테스트 3D와 BEV benchmark에서 single shot method보다 큰 차이로 성과를 보였다.
- 기존의 3D 객체 탐지에는 두가지 문제가 있다. 첫째, 기존 방법의 long-range 탐지 능력이 상대적으로 부족하다. 둘째, 이미지에서의 질감 정보를 충분히 사용하는 방법을 아직 모른다.
- Multi-task 학습은 3D 객체 탐지에서의 미래 과제이다. E.g., MMF는 multi-task를 포함하여 최고의 탐지 수행성과에 도달하기 위해 cross-modality 표현을 학습한다.
- 3D object tracking과 scene flow estimation은 부각되는 연구 주제이다. 그리고 2019년부터 점차 주목받고 있다.
5. 3D Point Cloud Segmentation
3D point cloud segmentation은 global geometric strcuture과 각 포인트의 fine-grained detail을 이해할 필요가 있다. segmentation granularity에 따르면, 3D point cloud segmentation은 세가지 종류로 구분된다: semantic segmentation(scene level), instance segmentation(object level), part segmentation(part level)
5.1 3D Semantic Segmentation
5.1.1 Projection-based Methods
5.1.2 Discretization-based Methods
5.1.3 Hybrid Methods
5.1.4 Point-based Methods
5.2 Instance Segmentation
semantic segmentation과 비교하여, instance segmentation은 더 정확하고 fine-grained한 point를 요구하는 아주 어려운 과제이다. 특히, 서로 다른 semantic meaning으로 구분하는 것과 더불어 같은 semantic meaning에서도 instance를 구분해야한다. 전반적으로, 기존 방식은 두가지 방법으로 나뉜다: propsal-based method와 propsal-free method. 몇몇 주요 알고리즘을 그림 13에 소개하였다.

5.2.1 Proposal-based Methods
이 방식은 instance segmentation 문제를 두개의 sub-task로 나눈다: 3D 객체 탐지와 instance mask prediction.
Hou et al.은 RGBD 입력값으로부터 semantic instance segmentation을 수행하기 위해 3D fully-convolutional semantic Instance Segmentation(3D-SIS) 네트워크를 제안했다. 이 네트워크는 색깔과 geometry 특징으로부터 학습한다. 3D 객체 탐지와 비슷하게, 3D region Proposal Network(3D-RPN)과 3D egion of Interesting(3D-RoI) 레이어는 bounding box 위치, 객체 클래스 레이블, instance mask를 예측하기 위해 사용되었다. analysis-by-synthesis 전략이 뒤를 이어, Yi et al.은 high-objectness 3D proposal을 생성하기 위해 Generative Shape Proposal Network(GSPN)을 제안하였다. 이 제안은 Regin-based PointNet(R-PointNet)에 의해 개선되었다. 레이블은 각 클래스 레이블마다 포인트별로 binary mask를 예측하여 얻어진다. point cloud로부터 3D bounding box의 direct regression과는 달리, 이 방식은 geometric 이해를 강화하여 많은 양의 의미없는 proposal을 제외한다.
2D panoptic segmentation을 3D mapping으로 확장시켜, Nariata et al.은 large-scale 3D reconstruction, semantic labeling, instance segmentation을 수행하기 위해 온라인 volumetric 3D mapping 시스템을 제안하였다. 그들은 먼저 2D semantic instance segmentation 네트워크를 사용하여 픽셀단위의 panoptic 레이블을 얻어내고, 이 레이블을 volumtric map에 합성하였다. fully-connected CRF는 정확한 segmentation을 수행하기 위해 사용되었다. 이 semantic mapping system은 고품질의 semantic mapping과 차별적인 객체 인식을 가능케 하였다. Yang et al.은 point cloud에서 instance segmentation을 수행하기 위해 3D-BoNet이라고 불리는 single-stage, anchor-free, end-to-end 학습 네트워크를 제안했다. 이 방법은 모든 잠재적 객체를 위해서 대략적으로 3D bounding box를 regress하고, 그리고나서 instance 레이블을 얻기위해 포인트단위의 이진 분류기를 사용하였다. 특히, bounding box 생성은 최선의 과제로서 형성되어있다. 게다가, multi-criteria loss function은 생성된 bounding box를 regularize하기 위해 제안되었다. 이 방식은 post-processing이 필요 없고, 계산에 있어 효율적이다. Zhang et al.은 large-scale 실외 라이다 point cloud의 instance segmentation을 위한 네트워크를 제안했다. 이 방식은 self-attention block을 사용하여 point cloud의 항공뷰에서 특징 표현을 학습한다. instance label은 예측된 수평선의 중심과 높이 제한을 기반으로 얻어진다. Shi et al.은 실내 3D 공간의 layout을 예측하기 위해 hierarchy-aware Variational Denoising Recursive AutoEncoder(VDRAE)를 제안했다. object proposal은 반복적으로 생성되며 recursive context aggregation과 propagation에 의해 개선된다.
전반적으로, proposal-based method는 직관적이고 straightforward하다. 그리고 instance segmentation 결과는 주로 객체를 잘 찾는다. 그런, 이 방법들은 multi-stage 학습과 수많은 proposal의 가지치기를 필요로한다. 그러므로, 이 방법은 주로 시간이 많이 소요되고, 계산이 복잡하고 많다.
5.2.2 Proposal-free Methods
Proposal-free method는 객체 탐지 모듈이 없다. 그 대신에, 이 방법은 주로 semantic segmentation 이후에 군집화 단계를 거쳐 instance segmentation을 고려한다. 특히, 가장 많이 존재하는 방식은 같은 instance에 속하는 포인트들은 매우 비슷한 특징을 지녀야한다는 가정을 기초로 한다. 그러므로, 이 방법은 주로 차별적인 특징 학습과 포인트 군집에 집중한다.
관련 연구에서, Wang et al.은 Similarity Group Proposal Network(SGPN)을 제안했다. 이 방법은 각 포인트마다 특징과 semantic map을 학습한다. 그리고 나서 각기 짝지어진 특징들 사이에서 유사성을 나타내고자 유사성 행렬을 소개한다. 더 차별적인 특징을 학습하기 위해, 그들은 유사성 행렬과 semantic segmentation 결과를 상호적으로 조절하기 위해 double-hinge loss를 사용한다. 마지막으로, instance 안에 유사한 포인트를 합치기 위해서 heuristic and non-maximal suppression 방식을 채택했다. 유사성 행렬을 생성하는데에 상당한 메모리가 소비되기 때문에, 이 방식의 적용이 다소 제한되어있다. 비슷하게, Liu et al.은 근처 voxel 사이에 각 복셀의 semantic 점수와 관련성을 예측하기 위해 submanifold sparse convolution을 사용했다. 그리고나서 예측 관련성과 mesh topology에 기반하여 instance에 포인트를 그룹짓기 위하여 군집화 알고리즘을 소개했다. Mo et al.은 instance segmentation을 수행하기 위해 PartNet에서 detection-by-segmentation 네트워크를 소개했다. 각 포인트의 semantic 레이블을 예측하고 instance mask를 disjoint하기 위해 PointNet++을 backbone으로 사용하였다. 게다가, Liang et al.은 차별적 embedding의 학습을 위한 structure-aware loss를 제안했다. 이 loss는 포인트 사이에 특징 유사도와 geometric 관계 모두를 고려한다. attention-based graph CNN은 이웃으로부터 서로다른 정보를 합쳐 학습된 특징을 개선하는데 사용되었다.
포인트의 semantic category와 instance label은 서로 의존적이기 때문에, 몇몇 방법들이 이 두가지 업무를 하나의 업무로 합치는 것을 제안하였다. 그 일환으로 Wang et al.은 end-to-end하고 학습가능한 Associatively Segmenting Instances and Semantics(ASIS) 모듀을 소개하였다. 실험은 semantic 특징과 instance 특징이 ASIS 모듈을 통해 개선된 성능에 도달하기 위해 서로 도움을 줄 수 있다고 말한다. 비슷하게, Zhao et al.은 semantic instance segmentation을 수행하기 위해 JSNet을 제안했다. 게다가, Pham et al.은
5.3 Part Segmentation
5.4 Summary
'논문 읽기' 카테고리의 다른 글